

▼音声認識使おうよ (^^) 入力にはコツもあるよ!
2018/01/02
たまたま音声認識の話になったので、iPhoneでいつも使っている様子をMacのQuickTimeで録画してみまし。若者の代表、学生も、あまり使いこなしている人がいないので、残念に思ってます。
すごく便利だから、使えるシチュエーションでは使ったほうが良いと思うのです。因みにマイクはiPhoneのときは下端についているので、自分の口の前に、水平にして話しかけます。

そのほか、音声認識は、CSRという原理で認識しているので、上手に入力するにはコツがいるんです。この秘訣を最後に書きますね。
音声認識は2002年ですらタイプの3.8倍も高速 かつ 肩こりレス
因みに僕は1999年の頃から、AmiVoice (アドバンスト・メディア社)という、とくに当時はぶっちぎりに超絶すごい性能の音声認識を使わせてもらっていて、論文も書きました(末尾にPDF)。このときの成績が以下の通り。表は英語になっているのでわかりにくいけど、右端を見てもらうと、放射線科医A(僕)は音声認識はタイプ入力に比べ1.4倍高速で、放射線科医Bは実に3.8倍も高速でした。
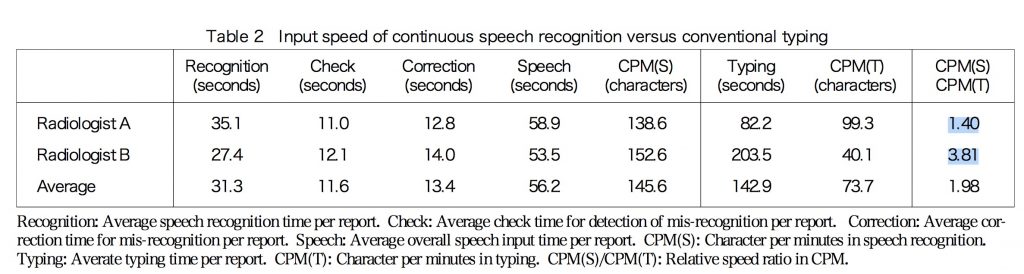
僕のタイプスピード(CPM; Character per minutes) は一分間に99.3文字。ワープロ検定1級(分速80文字)の合格ラインより25%高速なんです。自慢するようだけどこの速度の人はそんなに多くはないです。その人が全力で打っても、なお音声認識が2002年ですら1.4倍速かった。普通の人(分速40文字; 3級相当)だと3.8倍も速かった、ということなんです。
ところでタイプを全力ですると肩こりしますよね。だからそんなに長い時間、高速では打ちつづけられません。音声認識では肩こりも軽減されるので生産性も向上するんです。これが、Windows 95が出てすぐの頃に達成されていたというのは本当にオドロキです。

プロフェッショナルユースには「修正機能」のあるマイクが必須
なおAmiVoiceには、その後専用のマイクに対応し、それを使って修正するとすごく速く文章を修正できるようになったことがエポックメイキングでした。前述の論文は、タイプ修正していましたが、マイクでワンタッチ修正できるようになったので、さらに高速になったのです。
当時は高価なPHILIPS社製のディクテーションマイク(リンク)しかなかったけれど(しかし歴史があり完璧な製品)、今はAmiVoice Front SP01という廉価版マイクや、これをバンドルした汎用向けの製品(リンク)も出ています。「修正が一発でマイクで行える」ことがプロフェッショナルユースには必須だという考えは今でも変わりません。このマイクは安価になったと言っても35000円しますが、仕事で使うなら毎日膨大な修正を行うわけですから、これをケチるあまり、せっかくの音声認識なのに生産性が悪いのは、本当にもったいないことだと思います。

汎用音声認識の時代に
今は、iPhoneにしても、Macにしても、汎用の音声認識がかなり進歩しました。修正のための道具がないので、そこがしょぼいんだけど、それでもまあこんな風にはできるんです。間違ったところを、また音声認識で直す様子、それが難しいときだけタイプ修正する様子、わかりますでしょうか。
音声認識はリテラシー。だからトレーニングが必要
音声認識は、文章を考えながら「てん」「まる」「改行」なども言うのですが、これはひとつのリテラシー。すごく昔に、ワープロができることが新たなリテラシーだったのと同じように、これからは音声認識の入力速度というのもリテラシーの一つだと思います。
音声認識は、しかし、残念ながらシチュエーションを選びます。電車と新幹線では使わない(使えない)ですから、限定的な場所で使える道具ともいえますね。
ただ私は、電車のホーム、タクシーではまったく気にせず使うことにしています。いまは奇異にとられることもあります。しかし携帯がでたばかりの頃、ホームで(緑の公衆電話がホームにあるのに)携帯を敢えて使う人はすごく奇異に見られたんです。きっと、そのうち社会が変わると思います。最終的には想起のみで入る様になると思いますが、そうなれば便利ですね。
コツ:認識を上手にさせるには、「CSR」であることを意識しよう。
「音声認識はあまり入らない」と悩む人もいると思います。コツを教えますね。
CSRというのはContinuous Speech Recognition(連続音声認識*)と言います。ある単語が文章中ででてきたとき、音声認識システムは、その単語の前の発音と、後の発音を見て、もっとも出現確率が高いと思う単語に変換します(末尾の論文に説明あり)。
だから、音声認識をつかうときには、ひとつひとつ区切って発話するのは最悪の方法なんです。
ダメな方法 「きこなし」
良い方法 「あの人の着こなしは素敵だ」
「きこなし」 と単語でいうよりは、「あの人の着こなしは素敵だ」と行ったほうが、前後の単語(発音)があるぶん、コンピュータは理解しやすいのです。。
発話速度はどれだけ速くても良い
あと、発話速度ですが、テスラ(電気自動車のテスラ)でも、いま音声入力でナビの目的地を走行中にセットできますが(これは超便利。車を止めて目的地入力するなんて、、、と感じます)、こういったシーンでも、ゆっくり話す必要はまったくありません。
どれだけ速く話しても機械の方は認識します。だってWindows 95のときですら走ったぐらいなんですよ。いまはめちゃ余裕です。速い発話で問題になるのは、コンピュータの認識ではなくて、実は人間の誤発話なんです。あなたが正確に発音できる限り速く話してOKです。
僕の話し方は、長年の経験により、音声認識システムに認識してもらいやすく、かつ自分の発話が間違えない抑揚と速度で話しています。
苦手な人へ 〜 縄跳びを意識しよう
みなさんは小学生のときに縄跳びをして、二重跳びはできるようなりましたね。でも、大人になった今、たまにやってみると、3回は飛べるけど、10回連続して二重跳びに成功するのはなかなか難しいです。

音声認識もこれにとても良く似ています。もしあなたが、「おはようございますまる きょうはいいてんきですねまる」と連続発話して、きちんと変換されるなら、貴方の発音には問題ありません。
諦めないで繰り返して「連続して話す」ことをしていると、だんだんと認識精度が高くなります。ここに書いたことを意識して一週間も行えば、うんと成功率が高まることと思います。
ちなみに「連続して話す」には、ある程度の長さの文節を頭のなかで構築してから発話することになります。これがある意味での「リテラシー」である所以でもあります。ワープロができる前は、まず書くことを想起してからしましたね。「手書き」「ワープロ(タイプ)」「フリック」に加え、「音声認識」のリテラシーも獲得しましょう。
「連続音声認識によるレポート作成の試み」高原太郎ほか.NIPPON ACTA RADIOLOGICA 2002 ; 62 : 23-36 [PDF]
![]()
[論文中の記述から]
*連続音声認識の特徴と認識率: 連続音声認識は,単独の音声を変換するのではなく,前後の文脈(通常3語)の連携の特徴からもっとも出現確率の高い単語を予測する方法である 2).たとえば,「右_上肺野_ に_腫瘍_を_認める.」という文章と,「この_方法_は_主要 _な_もの_で_ある.」という 2つの文章に出現する「しゅよう」は前後の文脈の特徴により前者では「腫瘍」,後者では「主要」であることを出現確率から推定する.このため,従来の単語ベースの変換に比し,理論的にははるかに高い変換精度が得られる.
・認識率と修正時間: 小野木3)らは,いちはやく連続音声認識を用いた実験を行い先駆的な結果を残しているが,同法の問題点として,発話入力時間が極めて短い反面,修正時間が長くかかること を挙げている.すなわち,40語の文章の入力を10回試行し た平均値において,発話入力時間は19秒と高速であったが,確認・修正時間は48秒を要し,音声入力時間は67秒であった.これはキーボード入力の60秒よりも遅かった.このため修正方法が改善されればさらに高速になるであろうと推察している.このときの認識率は90%であった.しかしわれわれの実験結果では,修正に要する時間を考慮してもなおタイプ入力より高速であった.今回われわれの用いたシステムの認識率は97.1%であった.これは誤変換率に直すと,2.9%ということになる.一方認識率90%のシステムでは誤変換率は10%である.従って,誤変換率は1/3以下に減少したことになる.今回のわれわれのシステムでは, 修正方法は通常のワープロ上で行ったが,このような通常の修正方法であっても,誤認識率さえ低ければ修正の必要がなくなり,結果として入力速度が大幅に向上することを 示唆するものと思われる.また,今後,音声による修正や,次変換候補の自動表示ができれば,修正時間自体も短縮される可能性はあると思われる. → この後、マイクによるワンタッチ修正ができるようになった。
「02 デジタル, 25 音声認識」カテゴリーの人気記事

ギガファイル便で大容量データを送るときは「自分に」送ろう! 〜 DropBoxやGoogle ドライブよりも気軽に
大容量データを送るには、「DropBox」や「Google ドライブ」を利用する...

▼ MuseScoreで楽譜書きに挑戦 ♪
先週、はじめてコンピュータを用いて楽譜を作成してみました。 といっても、作曲し...
字幕とClosed Caption
ランニングマシーンでTVを見るときに字幕をON! あけましておめでとうございま...